
 데이터ㆍAI 시스템 아키텍트를 위한 실무 가이드
42,000원
중급
데이터ㆍAI 시스템 아키텍트를 위한 실무 가이드
42,000원
중급
도서 소개
저자 소개
목차
예제 코드
정오표
관련 자료
도서 소개
자세한 이론 설명과 파이썬 실습을 통해 머신러닝을 완벽하게 배울 수 있습니다!
《파이썬 머신러닝 완벽 가이드》는 이론 위주의 머신러닝 책에서 탈피해, 다양한 실전 예제를 직접 구현해 보면서 머신러닝을 체득할 수 있도록 만들었습니다. 캐글과 UCI 머신러닝 리포지토리에서 난이도가 있는 실습 데이터를 기반으로 실전 예제를 구성했고, XGBoost, LightGBM, 스태킹 기법 등 캐글의 많은 데이터 사이언스에서 애용하는 최신 알고리즘과 기법을 상세하게 설명했습니다.
이번 개정2판에서는 최신 사이킷런 버전(1.0.2)을 포함해 책에서 사용되는 모든 라이브러리를 최신 버전으로 업그레이드한 실습 코드를 구현하고, 다양한 유형의 하이퍼파라미터를 가지는 XGBoost나 LightGBM 모델의 최적 하이퍼파라미터 튜닝을 위한 베이지안 최적화 기법 적용 실습을 제공합니다. 또한 머신러닝 관련 데이터 분석에 널리 쓰이는 시각화 라이브러리인 matplotlib과 seaborn의 활용법을 다룬 장을 새롭게 추가했습니다.
★ 이 책의 특징 ★
- 분류, 회귀, 차원 축소, 클러스터링 등 핵심 머신러닝 알고리즘에 대한 깊이 있는 설명
- 데이터 전처리, 머신러닝 알고리즘 적용, 하이퍼 파라미터 튜닝, 성능 평가 등 최적 머신러닝 모델 구성 방안 제시
- XGBoost, LightGBM, 스태킹 등 머신러닝 최신 기법에 대한 상세한 설명과 활용법
- 난이도 높은 캐글 문제를 직접 따라 해 보면서 실무 머신러닝 애플리케이션 개발 방법 체득(산탄테르 은행 고객 만족 예측, 신용카드 사기 검출, 부동산 가격 예측 고급 회귀 기법, Mercari 쇼핑몰 가격 예측 등)
- 텍스트 분석과 NLP를 위한 기반 이론과 다양한 실습 예제 제공(텍스트 분류, 감성 분석, 토픽 모델링, 문서 유사도, 문서 군집화와 유사도, KoNLPy를 이용한 네이버 영화 감성 분석 등)
- 다양한 추천 시스템을 직접 파이썬 코드로 구축하는 법을 제공
도서 상세 이미지

저자 소개
권철민
엔코아 컨설팅, 한국 오라클을 거쳐 현재는 AI 프리랜서 컨설턴트로 활약하고 있다. 지난 20년간 50여 개 이상의 주요 고객사에서 데이터컨설팅 분야에 매진해 왔으며, 최근 몇 년간은 AI 기반의 Advanced Analytics 분야에 집중하고 있다. 직접 구현해 보지 않으면 절대 이해하지 못하는 평범한 두뇌의 소유자이며, 절망적인 프로젝트에 참여해 자기학대적인 노력으로 문제를 해결하는 이상한 성격의 소유자이기도 하다.
목차
- ▣ 1장: 파이썬 기반의 머신러닝과 생태계 이해
- 01. 머신러닝의 개념
- 머신러닝의 분류
- 데이터 전쟁
- 파이썬과 R 기반의 머신러닝 비교
- 02. 파이썬 머신러닝 생태계를 구성하는 주요 패키지
- 파이썬 머신러닝을 위한 S/W 설치
- 03. 넘파이
- 넘파이 ndarray 개요
- ndarray의 데이터 타입
- ndarray를 편리하게 생성하기 - arange, zeros, ones
- ndarray의 차원과 크기를 변경하는 reshape( )
- 넘파이의 ndarray의 데이터 세트 선택하기 – 인덱싱(Indexing)
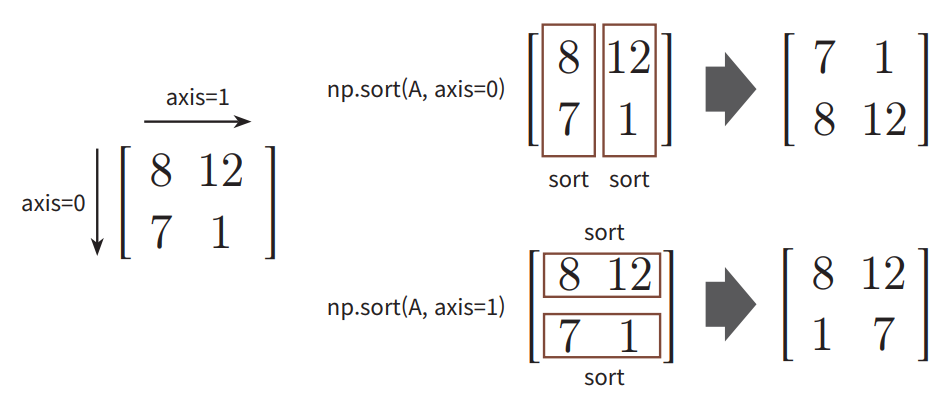
- 행렬의 정렬 – sort( )와 argsort( )
- 선형대수 연산 – 행렬 내적과 전치 행렬 구하기
- 04. 데이터 핸들링 - 판다스
- 판다스 시작 - 파일을 DataFrame으로 로딩, 기본 API
- DataFrame과 리스트, 딕셔너리, 넘파이 ndarray 상호 변환
- DataFrame의 칼럼 데이터 세트 생성과 수정
- DataFrame 데이터 삭제
- Index 객체
- 데이터 셀렉션 및 필터링
- 정렬, Aggregation 함수, GroupBy 적용
- 결손 데이터 처리하기
- apply lambda 식으로 데이터 가공
- 05. 정리
- 01. 머신러닝의 개념
- ▣ 2장: 사이킷런으로 시작하는 머신러닝
- 01. 사이킷런 소개와 특징
- 02. 첫 번째 머신러닝 만들어 보기 – 붓꽃 품종 예측하기
- 03. 사이킷런의 기반 프레임워크 익히기
- Estimator 이해 및 fit( ), predict( ) 메서드
- 사이킷런의 주요 모듈
- 내장된 예제 데이터 세트
- 04. Model Selection 모듈 소개
- 학습/테스트 데이터 세트 분리 – train_test_split()
- 교차 검증
- GridSearchCV – 교차 검증과 최적 하이퍼 파라미터 튜닝을 한 번에 111
- 05. 데이터 전처리
- 데이터 인코딩
- 피처 스케일링과 정규화
- StandardScaler
- MinMaxScaler
- 학습 데이터와 테스트 데이터의 스케일링 변환 시 유의점
- 06. 사이킷런으로 수행하는 타이타닉 생존자 예측
- 07. 정리
- ▣ 3장: 평가
- 01. 정확도(Accuracy)
- 02. 오차 행렬
- 03. 정밀도와 재현율
- 정밀도/재현율 트레이드오프
- 정밀도와 재현율의 맹점
- 04. F1 스코어
- 05. ROC 곡선과 AUC
- 06. 피마 인디언 당뇨병 예측
- 07. 정리
- ▣ 4장: 분류
- 01. 분류(Classification)의 개요
- 02. 결정 트리
- 결정 트리 모델의 특징
- 결정 트리 파라미터
- 결정 트리 모델의 시각화
- 결정 트리 과적합(Overfitting)
- 결정 트리 실습 – 사용자 행동 인식 데이터 세트
- 03. 앙상블 학습
- 앙상블 학습 개요
- 보팅 유형 – 하드 보팅(Hard Voting)과 소프트 보팅(Soft Voting)
- 보팅 분류기(Voting Classifier)
- 04. 랜덤 포레스트
- 랜덤 포레스트의 개요 및 실습
- 랜덤 포레스트 하이퍼 파라미터 및 튜닝
- GBM의 개요 및 실습
- 05. GBM(Gradient Boosting Machine)
- GBM 하이퍼 파라미터 소개
- XGBoost 개요
- 06. XGBoost(eXtra Gradient Boost)
- XGBoost 설치하기
- 파이썬 래퍼 XGBoost 하이퍼 파라미터
- 파이썬 래퍼 XGBoost 적용 – 위스콘신 유방암 예측
- 사이킷런 래퍼 XGBoost의 개요 및 적용
- 07. LightGBM
- LightGBM 설치
- LightGBM 하이퍼 파라미터
- 하이퍼 파라미터 튜닝 방안
- 파이썬 래퍼 LightGBM과 사이킷런 래퍼 XGBoost,
- LightGBM 하이퍼 파라미터 비교
- LightGBM 적용 – 위스콘신 유방암 예측
- 08. 베이지안 최적화 기반의 HyperOpt를 이용한 하이퍼 파라미터 튜닝
- 베이지안 최적화 개요
- HyperOpt 사용하기
- HyperOpt를 이용한 XGBoost 하이퍼 파라미터 최적화
- 09. 분류 실습 - 캐글 산탄데르 고객 만족 예측
- 데이터 전처리
- XGBoost 모델 학습과 하이퍼 파라미터 튜닝
- LightGBM 모델 학습과 하이퍼 파라미터 튜닝
- 10. 분류 실습 – 캐글 신용카드 사기 검출
- 언더 샘플링과 오버 샘플링의 이해
- 데이터 일차 가공 및 모델 학습/예측/평가
- 데이터 분포도 변환 후 모델 학습/예측/평가
- 이상치 데이터 제거 후 모델 학습/예측/평가
- SMOTE 오버 샘플링 적용 후 모델 학습/예측/평가
- 11. 스태킹 앙상블
- 기본 스태킹 모델
- CV 세트 기반의 스태킹
- 12. 정리
- ▣ 5장: 회귀
- 01. 회귀 소개
- 02. 단순 선형 회귀를 통한 회귀 이해
- 03. 비용 최소화하기 – 경사 하강법(Gradient Descent) 소개
- 04. 사이킷런 LinearRegression을 이용한 보스턴 주택 가격 예측
- LinearRegression 클래스 - Ordinary Least Squares
- 회귀 평가 지표
- LinearRegression을 이용해 보스턴 주택 가격 회귀 구현
- 05. 다항 회귀와 과(대)적합/과소적합 이해
- 다항 회귀 이해
- 다항 회귀를 이용한 과소적합 및 과적합 이해
- 편향-분산 트레이드오프(Bias-Variance Trade off)
- 06. 규제 선형 모델 – 릿지, 라쏘, 엘라스틱넷
- 규제 선형 모델의 개요
- 릿지 회귀
- 라쏘 회귀
- 엘라스틱넷 회귀
- 선형 회귀 모델을 위한 데이터 변환
- 07. 로지스틱 회귀
- 08. 회귀 트리
- 09. 회귀 실습 – 자전거 대여 수요 예측
- 데이터 클렌징 및 가공과 데이터 시각화
- 로그 변환, 피처 인코딩과 모델 학습/예측/평가
- 10. 회귀 실습 – 캐글 주택 가격: 고급 회귀 기법
- 데이터 사전 처리(Preprocessing)
- 선형 회귀 모델 학습/예측/평가
- 회귀 트리 모델 학습/예측/평가
- 회귀 모델의 예측 결과 혼합을 통한 최종 예측
- 스태킹 앙상블 모델을 통한 회귀 예측
- 11. 정리
- ▣ 6장: 차원 축소
- 01. 차원 축소(Dimension Reduction) 개요
- 02. PCA(Principal Component Analysis)
- PCA 개요
- 03. LDA(Linear Discriminant Analysis)
- LDA 개요
- 04. SVD(Singular Value Decomposition)
- SVD 개요
- 사이킷런 TruncatedSVD 클래스를 이용한 변환
- 05. NMF(Non-Negative Matrix Factorization)
- NMF 개요
- 06. 정리
- ▣ 7장: 군집화
- 01. K-평균 알고리즘 이해
- 사이킷런 KMeans 클래스 소개
- K-평균을 이용한 붓꽃 데이터 세트 군집화
- 군집화 알고리즘 테스트를 위한 데이터 생성
- 02. 군집 평가(Cluster Evaluation)
- 실루엣 분석의 개요
- 붓꽃 데이터 세트를 이용한 군집 평가
- 군집별 평균 실루엣 계수의 시각화를 통한 군집 개수 최적화 방법
- 03. 평균 이동
- 평균 이동(Mean Shift)의 개요
- 04. GMM(Gaussian Mixture Model)
- GMM(Gaussian Mixture Model) 소개
- GMM을 이용한 붓꽃 데이터 세트 군집화
- GMM과 K-평균의 비교
- 05. DBSCAN
- DBSCAN 개요
- DBSCAN 적용하기 – 붓꽃 데이터 세트
- DBSCAN 적용하기 – make_circles( ) 데이터 세트
- 06. 군집화 실습 – 고객 세그먼테이션
- 고객 세그먼테이션의 정의와 기법
- 데이터 세트 로딩과 데이터 클렌징
- RFM 기반 데이터 가공
- RFM 기반 고객 세그먼테이션
- 07. 정리
- 01. K-평균 알고리즘 이해
- ▣ 8장 텍스트 분석
- NLP이냐 텍스트 분석이냐?
- 01. 텍스트 분석 이해
- 텍스트 분석 수행 프로세스
- 파이썬 기반의 NLP, 텍스트 분석 패키지
- 02. 텍스트 사전 준비 작업(텍스트 전처리) - 텍스트 정규화
- 클렌징
- 텍스트 토큰화
- 스톱 워드 제거
- Stemming과 Lemmatization
- 03. Bag of Words – BOW
- BOW 피처 벡터화
- 사이킷런의 Count 및 TF-IDF 벡터화 구현: CountVectorizer, TfidfVectorizer
- BOW 벡터화를 위한 희소 행렬
- 희소 행렬 - COO 형식
- 희소 행렬 – CSR 형식
- 04. 텍스트 분류 실습 – 20 뉴스그룹 분류
- 텍스트 정규화
- 피처 벡터화 변환과 머신러닝 모델 학습/예측/평가
- 사이킷런 파이프라인(Pipeline) 사용 및 GridSearchCV와의 결합
- 05. 감성 분석
- 감성 분석 소개
- 지도학습 기반 감성 분석 실습 – IMDB 영화평
- 비지도학습 기반 감성 분석 소개
- SentiWordNet을 이용한 감성 분석
- VADER를 이용한 감성 분석
- 06. 토픽 모델링(Topic Modeling) - 20 뉴스그룹
- 07. 문서 군집화 소개와 실습(Opinion Review 데이터 세트)
- 문서 군집화 개념
- Opinion Review 데이터 세트를 이용한 문서 군집화 수행하기
- 군집별 핵심 단어 추출하기
- 08. 문서 유사도
- 문서 유사도 측정 방법 – 코사인 유사도
- 두 벡터 사잇각
- Opinion Review 데이터 세트를 이용한 문서 유사도 측정
- 09. 한글 텍스트 처리 – 네이버 영화 평점 감성 분석
- 한글 NLP 처리의 어려움
- KoNLPy 소개
- 데이터 로딩
- 10. 텍스트 분석 실습 – 캐글 Mercari Price Suggestion Challenge
- 데이터 전처리
- 피처 인코딩과 피처 벡터화
- 릿지 회귀 모델 구축 및 평가
- LightGBM 회귀 모델 구축과 앙상블을 이용한 최종 예측 평가
- 11. 정리
- NLP이냐 텍스트 분석이냐?
- ▣ 9장: 추천 시스템
- 01. 추천 시스템의 개요와 배경
- 추천 시스템의 개요
- 온라인 스토어의 필수 요소, 추천 시스템
- 추천 시스템의 유형
- 02. 콘텐츠 기반 필터링 추천 시스템
- 03. 최근접 이웃 협업 필터링
- 04. 잠재 요인 협업 필터링
- 잠재 요인 협업 필터링의 이해
- 행렬 분해의 이해
- 확률적 경사 하강법을 이용한 행렬 분해
- 05. 콘텐츠 기반 필터링 실습 – TMDB 5000 영화 데이터 세트
- 장르 속성을 이용한 영화 콘텐츠 기반 필터링
- 데이터 로딩 및 가공
- 장르 콘텐츠 유사도 측정
- 장르 콘텐츠 필터링을 이용한 영화 추천
- 06. 아이템 기반 최근접 이웃 협업 필터링 실습
- 데이터 가공 및 변환
- 영화 간 유사도 산출
- 아이템 기반 최근접 이웃 협업 필터링으로 개인화된 영화 추천
- 07. 행렬 분해를 이용한 잠재 요인 협업 필터링 실습
- Surprise 패키지 소개
- 08. 파이썬 추천 시스템 패키지 - Surprise
- Surprise를 이용한 추천 시스템 구축
- Surprise 주요 모듈 소개
- Surprise 추천 알고리즘 클래스
- 베이스라인 평점
- 교차 검증과 하이퍼 파라미터 튜닝
- Surprise를 이용한 개인화 영화 추천 시스템 구축
- 09. 정리
- 01. 추천 시스템의 개요와 배경
- ▣ 10장: 시각화
- 01. 시각화를 시작하며 – 맷플롯립과 시본 개요
- 02. 맷플롯립(Matplotlib)
- 맷플롯립의 pyplot 모듈의 이해
- pyplot의 두 가지 중요 요소 – Figure와 Axes 이해
- Figure와 Axis의 활용
- 여러 개의 plot을 가지는 subplot들을 생성하기
- pyplot의 plot( ) 함수를 이용해 선 그래프 그리기
- 축 명칭 설정, 축의 눈금(틱)값 회전, 범례(legend) 설정하기
- 여러 개의 subplots들을 이용해 개별 그래프들을 subplot별로 시각화하기
- 03. 시본(Seaborn)
- 시각화를 위한 차트/그래프 유형
- 정보의 종류에 따른 시각화 차트 유형
- 히스토그램(Histogram)
- 카운트 플롯
- 바 플롯(barplot)
- barplot( ) 함수의 hue 인자를 사용하여 시각화 정보를 추가적으로 세분화하기
- 박스 플롯
- 바이올린 플롯
- subplots를 이용하여 시본의 다양한 그래프를 시각화
- 산점도, 스캐터 플롯(Scatter Plot)
- 상관 히트맵(Correlation Heatmap)
- 04. 정리
예제 코드
- GitHub 저장소: https://github.com/wikibook/pymlrev2
- ZIP 형식으로 다운로드: https://github.com/wikibook/pymlrev2/archive/refs/heads/main.zip
정오표
4쇄
-
81쪽, 본문 밑에서 3번째 줄
나이가 15세
미만이면==>
나이가 15세
이하면 -
379쪽, 본문 1~7번째 줄
이제 문자형 피처를 제외하고는 Null 값이 없습니다.
문자형 피처는 모두 원-핫 인코딩으로 변환하겠습니다. 원-핫 인코딩은 판다스의 get_dummies( )를 이용하겠습니다. get_dummies( )는 자동으로 문자열 피처를 원-핫 인코딩 변환하면서 Null 값은 이제 문자형 피처를 제외하고는 Null 값이 없습니다.문자형 피처는 모두 원-핫 인코딩으로 변환하겠습니다. 원-핫 인코딩은 판다스의 get_dummies( )를 이용하겠습니다. get_dummies( )는 자동으로 문자열 피처를 원-핫 인코딩 변환하면서 Null 값은 모든 인코딩 값이 0으로 변환되는 방식으로 대체해주므로 별도의 Null 값을 대체하는 로직이 필요 없습니다.==>
이제 문자형 피처를 제외하고는 Null 값이 없습니다. 문자형 피처는 모두 원-핫 인코딩으로 변환하겠습니다. 원-핫 인코딩은 판다스의 get_dummies( )를 이용하겠습니다. get_dummies( )는 자동으로 문자열 피처를 원-핫 인코딩 변환하면서 Null 값은 모든 인코딩 값이 0으로 변환되는 방식으로 대체해주므로 별도의 Null 값을 대체하는 로직이 필요 없습니다.
3쇄
-
81쪽, 본문 밑에서 3번째 줄
나이가 15세
미만이면==>
나이가 15세
이하면 -
287쪽, 본문 2번째 줄
조금 저하되었고,
LightGM의 경우는==>
조금 저하되었고,
LightGBM의 경우는 -
316쪽, 본문 밑에서 6번째 줄
getweight
update( ) 함수에서,==>
getweight
updates( ) 함수에서, -
329쪽, 본문 첫 번째 줄
평균 RMSE는 약
5.5829이나왔습니다.==>
평균 RMSE는 약
5.829가나왔습니다. -
344쪽, 본문 첫 번째 줄
alpha가 0.07일 때
5.618로 가장 좋은 평균 RMSE를 보여줍니다. 앞의 릿지 평균5.5118보다는 약간 떨어지는 수치지만,==>
alpha가 0.07일 때
5.612로 가장 좋은 평균 RMSE를 보여줍니다. 앞의 릿지 평균5.518보다는 약간 떨어지는 수치지만, -
353쪽, 페이지 상단 첫 번째 예제 코드의 2~6번째 줄
lr_preds = lr_clf.predict(X_test) # accuracy와 roc_auc 측정 print('accuracy: {0:.3f}, roc_auc:{1:.3f}'.format(accuracy_score(y_test, lr_preds), roc_auc_score(y_test , lr_preds)))==>
lr_preds = lr_clf.predict(X_test) lr_preds_proba = lr_clf.predict_proba(X_test)[:, 1] # accuracy와 roc_auc 측정 print('accuracy: {0:.3f}, roc_auc:{1:.3f}'.format(accuracy_score(y_test, lr_preds), roc_auc_score(y_test , lr_preds_proba))) -
353쪽, 페이지 상단 Output
accuracy: 0.977, roc_auc:0.972==>
accuracy: 0.977, roc_auc:0.995 -
353쪽, 본문 첫 번째 줄
ROC-AUC가
0.972로 도출되었습니다.==>
ROC-AUC가
0.995로 도출되었습니다. -
353쪽, 페이지 하단 예제 코드의 7~12번째 줄
lr_preds = lr_clf.predict(X_test) # accuracy와 roc_auc 측정 print('solver:{0}, accuracy: {1:.3f}, roc_auc:{2:.3f}'.format(solver, accuracy_score(y_test, lr_preds), roc_auc_score(y_test , lr_preds)))==>
lr_preds = lr_clf.predict(X_test) lr_preds_proba = lr_clf.predict_proba(X_test)[:, 1] # accuracy와 roc_auc 측정 print('solver:{0}, accuracy: {1:.3f}, roc_auc:{2:.3f}'.format(solver, accuracy_score(y_test, lr_preds), roc_auc_score(y_test , lr_preds_proba))) -
353쪽, 페이지 하단 Output
solver:lbfgs, accuracy: 0.977, roc_auc:0.972 solver:liblinear, accuracy: 0.982, roc_auc:0.979 solver:newton-cg, accuracy: 0.977, roc_auc:0.972 solver:sag, accuracy: 0.982, roc_auc:0.979 solver:saga, accuracy: 0.982, roc_auc:0.979==>
solver:lbfgs, accuracy: 0.977, roc_auc:0.995 solver:liblinear, accuracy: 0.982, roc_auc:0.995 solver:newton-cg, accuracy: 0.977, roc_auc:0.995 solver:sag, accuracy: 0.982, roc_auc:0.995 solver:saga, accuracy: 0.982, roc_auc:0.995 -
354쪽, 본문 첫 번째 줄
ROC-AUC가
0.979로==>
ROC-AUC가
0.995로 -
367쪽, 본문 4번째 줄
RMSLE뿐만 아니라
MSE, RMSE까지==>
RMSLE뿐만 아니라
MAE, RMSE까지 -
367쪽, 첫 번째 예제 코드의 밑에서 7번째 줄
# MSE, RMSE, RMSLE를 모두 계산==>
# MAE, RMSE, RMSLE를 모두 계산 -
368쪽, 본문 첫째 줄
따라서 log( )보다는 log1p( )를 이용하는데, log1p( )의 경우는 1+ log( ) 값으로 log 변환값에 1을 더하므로 이런 문제를 해결해 줍니다.
==>
따라서 log( )보다는 log1p( )를 이용하는데, log1p(x)의 경우는 log(1+x)로 변환되므로 x값이 0이 되더라도 log(0)인 무한대가 되지 않고, log(1)인 0이 되므로 오버플로/언더플로 문제를 해결해 줍니다.
-
368쪽, 본문 밑에서 3번째 줄
RMSLE: 1.165, RMSE: 140.900,
MSE: 105.924는==>
RMSLE: 1.165, RMSE: 140.900,
MAE: 105.924는 -
379쪽, 본문 1~7번째 줄
이제 문자형 피처를 제외하고는 Null 값이 없습니다.
문자형 피처는 모두 원-핫 인코딩으로 변환하겠습니다. 원-핫 인코딩은 판다스의 get_dummies( )를 이용하겠습니다. get_dummies( )는 자동으로 문자열 피처를 원-핫 인코딩 변환하면서 Null 값은 이제 문자형 피처를 제외하고는 Null 값이 없습니다.문자형 피처는 모두 원-핫 인코딩으로 변환하겠습니다. 원-핫 인코딩은 판다스의 get_dummies( )를 이용하겠습니다. get_dummies( )는 자동으로 문자열 피처를 원-핫 인코딩 변환하면서 Null 값은 모든 인코딩 값이 0으로 변환되는 방식으로 대체해주므로 별도의 Null 값을 대체하는 로직이 필요 없습니다.==>
이제 문자형 피처를 제외하고는 Null 값이 없습니다. 문자형 피처는 모두 원-핫 인코딩으로 변환하겠습니다. 원-핫 인코딩은 판다스의 get_dummies( )를 이용하겠습니다. get_dummies( )는 자동으로 문자열 피처를 원-핫 인코딩 변환하면서 Null 값은 모든 인코딩 값이 0으로 변환되는 방식으로 대체해주므로 별도의 Null 값을 대체하는 로직이 필요 없습니다.
-
565쪽, 페이지 하단 예제 코드의 밑에서 첫 번째 줄
print('Logistic Regression 정확도: ', accuracy_score(test_df['label'], preds)==>
print('Logistic Regression 정확도: ', accuracy_score(test_df['label'], preds))
초판 ~ 2쇄
-
16쪽, 페이지 중간 예제 코드
print('array1: {:0}차원, array2: {:1}차원, array3: {:2}차원'.format(array1.ndim, array2.ndim, array3.ndim))==>
print('array1: {0}차원, array2: {1}차원, array3: {2}차원'.format(array1.ndim, array2.ndim, array3.ndim)) -
34쪽, 페이지 하단 그림을 아래 그림으로 교체

-
75쪽, 본문 7번째 줄
DataFrame Groupby객체를 반환합니다.==>
DataFrameGroupby객체를 반환합니다. -
81쪽, 본문 밑에서 3번째 줄
나이가 15세
미만이면==>
나이가 15세
이하면 -
86쪽, 본문 3번째 줄(중복 문장 삭제)
1장에서 말한 바와 같이 Anaconda를 설치하면 기본으로 사이킷런까지 설치가 완료되기에 별도의 설치가 필요 없습니다.1장에서 말한 바와 같이 Anaconda를 설치하면 기본으로 사이킷런까지 설치가 완료되기에 별도의 설치가 필요 없습니다.==>
1장에서 말한 바와 같이 Anaconda를 설치하면 기본으로 사이킷런까지 설치가 완료되기에 별도의 설치가 필요 없습니다.
-
89쪽, 본문 밑에서 10번째 줄
숫자 자체는 어떤
값은지정해도==>
숫자 자체는 어떤
값을지정해도 -
95쪽, 본문 밑에서 3번째 줄
파이썬 리스트(list)
타입니다.==>
파이썬 리스트(list)
타입입니다. -
96쪽, 본문 밑에서 2번째 줄
load_
irs( )가 반환하는==>
load_
iris( )가 반환하는 -
157쪽, 페이지 상단 Output을 다음 내용으로 교체
오차 행렬 [[108 10] [ 14 47]] 정확도: 0.8659, 정밀도: 0.8246, 재현율: 0.7705 -
175쪽, 예제 코드의 9번째 줄
lr_clf = LogisticRegression(solver='linear')==>
lr_clf = LogisticRegression(solver='liblinear') -
192쪽, 페이지 상단 불릿 목록의 4번째 항목 3번째 줄
Vesicolor40개, Virginica 39개로==>
Versicolor40개, Virginica 39개로 -
193쪽, 페이지 상단 두 번째 불릿 목록의 첫 번째 항목
79개의 샘플 데이터 중
Vesicolor40개,==>
79개의 샘플 데이터 중
Versicolor40개, -
236쪽, 본문 밑에서 첫 번째 줄
하지만 num_boost_round를
500회로 설정했음에도 불구하고 학습은500번을==>
하지만 num_boost_round를
400회로 설정했음에도 불구하고 학습은400번을 -
238쪽, 페이지 하단에 다음 코드를 추가
import matplotlib.pyplot as plt %matplotlib inline fig, ax = plt.subplots(figsize=(10, 12)) plot_importance(xgb_model, ax=ax) -
242쪽, 본문 밑에서 4번째 줄
early_stopping_rounds를
100, eval_metric은 logloss를 설정하고,==>
early_stopping_rounds를
50, eval_metric은 logloss를 설정하고, -
244쪽, 본문 4번째 줄
stopping_rounds=
100일 때의 약 0.9561보다 낮습니다.==>
stopping_rounds=
50일 때의 약 0.9561보다 낮습니다. -
244쪽, 본문 7번째 줄 하단에 다음과 같이 코드를 추가
출력 결과는 책에 수록하지 않겠습니다.
==>
출력 결과는 책에 수록하지 않겠습니다.
from xgboost import plot_importance import matplotlib.pyplot as plt %matplotlib inline fig, ax = plt.subplots(figsize=(10, 12)) # 사이킷런 래퍼 클래스를 입력해도 무방. plot_importance(xgb_wrapper, ax=ax) -
254쪽, 본문 밑에서 10번째 줄
베이지안
최적화는구성하는==>
베이지안
최적화를구성하는 -
263쪽, 본문 7번째 줄
설정한하이퍼파라미터들을 입력받아서==>
설정한 하이퍼파라미터들을 입력받아서 -
286쪽, 2번째 예제 코드의 밑에서 2번째 줄
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=64, n_jobs=-1)==>
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=64, n_jobs=-1, boost_from_average=False) -
287쪽, 본문 2번째 줄
조금 저하되었고,
LightGM의 경우는==>
조금 저하되었고,
LightGBM의 경우는 -
298쪽, 페이지 하단 예제 코드의 아래 6번째 줄 삭제
gbm_pred = gbm_clf.predict(X_test) -
314쪽, 페이지 중간 수식을 다음 수식으로 교체(닫는 괄호 추가)
$ \frac{\partial R(w)}{\partial w1} = \frac{2}{N} \sum{i=1}^{N} - x_t (y_i - (w_0 + w_1 xi)) = - \frac{2}{N} \sum{i=1}^{N} x_i (실제값_i - 예측값_i) $
$ \frac{\partial R(w)}{\partial w0} = \frac{2}{N} \sum{i=1}^{N} - (y_i - (w_0 + w_1 xi)) = - \frac{2}{N} \sum{i=1}^{N} (실제값_i - 예측값_i) $
-
316쪽, 본문 밑에서 6번째 줄
getweight
update( ) 함수에서,==>
getweight
updates( ) 함수에서, -
319쪽, 페이지 상단 예제 코드의 다음 1~2줄을 삭제
prev_cost = 100000 iter_index =0 -
329쪽, 본문 첫 번째 줄
평균 RMSE는 약
5.5829이나왔습니다.==>
평균 RMSE는 약
5.829가나왔습니다. -
341쪽, 본문 2번째 줄
Ridge 객체의 coef_
속성에추출한 뒤에==>
Ridge 객체의 coef_
속성에서추출한 뒤에 -
344쪽, 본문 첫 번째 줄
alpha가 0.07일 때
5.618로 가장 좋은 평균 RMSE를 보여줍니다. 앞의 릿지 평균5.5118보다는 약간 떨어지는 수치지만,==>
alpha가 0.07일 때
5.612로 가장 좋은 평균 RMSE를 보여줍니다. 앞의 릿지 평균5.518보다는 약간 떨어지는 수치지만, -
348쪽, 예제 코드의 상단에 다음 코드를 추가
from sklearn.preprocessing import StandardScaler, MinMaxScaler, PolynomialFeatures -
351쪽, 페이지 중간 불릿 목록의 3번째 항목
newton-cg
::좀 더 정교한 최적화를==>
newton-cg
:좀 더 정교한 최적화를 -
353쪽, 페이지 상단 첫 번째 예제 코드의 2~6번째 줄
lr_preds = lr_clf.predict(X_test) # accuracy와 roc_auc 측정 print('accuracy: {0:.3f}, roc_auc:{1:.3f}'.format(accuracy_score(y_test, lr_preds), roc_auc_score(y_test , lr_preds)))==>
lr_preds = lr_clf.predict(X_test) lr_preds_proba = lr_clf.predict_proba(X_test)[:, 1] # accuracy와 roc_auc 측정 print('accuracy: {0:.3f}, roc_auc:{1:.3f}'.format(accuracy_score(y_test, lr_preds), roc_auc_score(y_test , lr_preds_proba))) -
353쪽, 페이지 상단 Output
accuracy: 0.977, roc_auc:0.972==>
accuracy: 0.977, roc_auc:0.995 -
353쪽, 본문 첫 번째 줄
ROC-AUC가
0.972로 도출되었습니다.==>
ROC-AUC가
0.995로 도출되었습니다. -
353쪽, 페이지 하단 예제 코드의 7~12번째 줄
lr_preds = lr_clf.predict(X_test) # accuracy와 roc_auc 측정 print('solver:{0}, accuracy: {1:.3f}, roc_auc:{2:.3f}'.format(solver, accuracy_score(y_test, lr_preds), roc_auc_score(y_test , lr_preds)))==>
lr_preds = lr_clf.predict(X_test) lr_preds_proba = lr_clf.predict_proba(X_test)[:, 1] # accuracy와 roc_auc 측정 print('solver:{0}, accuracy: {1:.3f}, roc_auc:{2:.3f}'.format(solver, accuracy_score(y_test, lr_preds), roc_auc_score(y_test , lr_preds_proba))) -
353쪽, 페이지 하단 Output
solver:lbfgs, accuracy: 0.977, roc_auc:0.972 solver:liblinear, accuracy: 0.982, roc_auc:0.979 solver:newton-cg, accuracy: 0.977, roc_auc:0.972 solver:sag, accuracy: 0.982, roc_auc:0.979 solver:saga, accuracy: 0.982, roc_auc:0.979==>
solver:lbfgs, accuracy: 0.977, roc_auc:0.995 solver:liblinear, accuracy: 0.982, roc_auc:0.995 solver:newton-cg, accuracy: 0.977, roc_auc:0.995 solver:sag, accuracy: 0.982, roc_auc:0.995 solver:saga, accuracy: 0.982, roc_auc:0.995 -
354쪽, 본문 첫 번째 줄
ROC-AUC가
0.979로==>
ROC-AUC가
0.995로 -
354쪽, 첫 번째 예제 코드의 5번째 줄
'C':[0.01, 0.1, 1, 1, 5, 10]}==>
'C':[0.01, 0.1, 1, 5, 10]} -
354쪽, 두 번째 예제 코드의 4번째 줄
18 fits failed out of a total of 72.==>
15 fits failed out of a total of 60. -
367쪽, 본문 4번째 줄
RMSLE뿐만 아니라
MSE, RMSE까지==>
RMSLE뿐만 아니라
MAE, RMSE까지 -
367쪽, 첫 번째 예제 코드의 밑에서 7번째 줄
# MSE, RMSE, RMSLE를 모두 계산==>
# MAE, RMSE, RMSLE를 모두 계산 -
368쪽, 본문 첫째 줄
따라서 log( )보다는 log1p( )를 이용하는데, log1p( )의 경우는 1+ log( ) 값으로 log 변환값에 1을 더하므로 이런 문제를 해결해 줍니다.
==>
따라서 log( )보다는 log1p( )를 이용하는데, log1p(x)의 경우는 log(1+x)로 변환되므로 x값이 0이 되더라도 log(0)인 무한대가 되지 않고, log(1)인 0이 되므로 오버플로/언더플로 문제를 해결해 줍니다.
-
368쪽, 본문 밑에서 3번째 줄
RMSLE: 1.165, RMSE: 140.900,
MSE: 105.924는==>
RMSLE: 1.165, RMSE: 140.900,
MAE: 105.924는 -
373쪽, 본문 3번째 줄
계수 상위
25개 피처를 추출해 보겠습니다.==>
계수 상위
20개 피처를 추출해 보겠습니다. -
379쪽, 본문 1~7번째 줄
이제 문자형 피처를 제외하고는 Null 값이 없습니다.
문자형 피처는 모두 원-핫 인코딩으로 변환하겠습니다. 원-핫 인코딩은 판다스의 get_dummies( )를 이용하겠습니다. get_dummies( )는 자동으로 문자열 피처를 원-핫 인코딩 변환하면서 Null 값은 이제 문자형 피처를 제외하고는 Null 값이 없습니다.문자형 피처는 모두 원-핫 인코딩으로 변환하겠습니다. 원-핫 인코딩은 판다스의 get_dummies( )를 이용하겠습니다. get_dummies( )는 자동으로 문자열 피처를 원-핫 인코딩 변환하면서 Null 값은 모든 인코딩 값이 0으로 변환되는 방식으로 대체해주므로 별도의 Null 값을 대체하는 로직이 필요 없습니다.==>
이제 문자형 피처를 제외하고는 Null 값이 없습니다. 문자형 피처는 모두 원-핫 인코딩으로 변환하겠습니다. 원-핫 인코딩은 판다스의 get_dummies( )를 이용하겠습니다. get_dummies( )는 자동으로 문자열 피처를 원-핫 인코딩 변환하면서 Null 값은 모든 인코딩 값이 0으로 변환되는 방식으로 대체해주므로 별도의 Null 값을 대체하는 로직이 필요 없습니다.
-
380쪽, 본문 첫 번째 줄
75개에서
272개로 증가했습니다.==>
75개에서
271개로 증가했습니다. -
382쪽, 본문 4번째 줄
생성한
get_top_bottoms(model, n=10 ) 함수를 이용해==>
생성한
get_top_bottom_coef(model, n=10 ) 함수를 이용해 -
461쪽, 두 번째 예제 코드의 마지막 줄
visualize_cluster_plot(kmeans, clusterDF, 'kmeans_label', iscluster=True)==>
visualize_cluster_plot(kmeans, clusterDF, 'kmeans_label', iscenter=True) -
462쪽, 첫 번째 예제 코드의 마지막 2줄
# GaussianMixture는 cluster_centers_ 속성이 없으므로 iscluster를 False로 설정. visualize_cluster_plot(gmm, clusterDF, 'gmm_label', iscluster=False)==>
# GaussianMixture는 cluster_centers_ 속성이 없으므로 iscenter를 False로 설정. visualize_cluster_plot(gmm, clusterDF, 'gmm_label', iscenter=False) -
468쪽, 본문 밑에서 2번째 줄
visualize_cluster_2d( )함수 인자로 사용하기 위해==>
visualize_cluster_plot( )함수 인자로 사용하기 위해 irisDF의 ‘ftr1’, -
468쪽, 페이지 하단 예제 코드의 5번째 줄
# visualize_cluster_2d( ) 함수는==>
# visualize_cluster_plot( ) 함수는 -
484쪽, 본문 3번째 줄
visualized_silhouette( )함수와 군집 개수별로==>
visualize_silhouette( )함수와 군집 개수별로 -
512쪽, 페이지 상단 예제 코드의 4번째 줄
fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'),==>
train_news = fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'), -
513쪽, 페이지 상단 예제 코드의 밑에서 4번째 줄
# 학습 데이터로 fit( )된 CountVectorizer를 이용해 테스트 데이터를 피터 벡처화 변환 수행.==>
# 학습 데이터로 fit( )된 CountVectorizer를 이용해 테스트 데이터를 피터 벡터화 변환 수행. -
515쪽, 본문 밑에서 2번째 줄
이를 테스트 데이터 세트에 적용해 약
0.703으로==>
이를 테스트 데이터 세트에 적용해 약
0.704로 -
522쪽, 페이지 하단 예제 코드의 다음 6번째 줄
# 스톱 워드는 English, filtering, ngram은 (1, 2)로 설정해 CountVectorization 수행.==>
# 스톱 워드는 English, ngram은 (1, 2)로 설정해 CountVectorization 수행. -
524쪽, 본문 첫 번째 줄
상세히 이해하기 위해
NLP패키지의==>
상세히 이해하기 위해
NLTK패키지의 -
524쪽, 본문 2번째 줄
NLP에서 제공하는 WordNet 모듈은==>
NLTK에서 제공하는 WordNet 모듈은 -
529쪽, 페이지 하단 숫자 목록의 4번째 항목
Senti_synset에서 긍정 감성/부정 감성 지수를 구하고
==>
senti_synset에서 긍정 감성/부정 감성 지수를 구하고
-
531쪽, 두 번째 예제 코드
train_df['preds'] = train_df['review'].apply( lambda x : swn_polarity(x) ) y_target = train_df['sentiment'].values preds = train_df['preds'].values==>
review_df['preds'] = review_df['review'].apply( lambda x : swn_polarity(x) ) y_target = review_df['sentiment'].values preds = review_df['preds'].values -
532쪽, 페이지 하단 예제 코드의 4번째 줄
senti_scores = senti_analyzer.polarity_scores(train_df['review'][0])==>
senti_scores = senti_analyzer.polarity_scores(review_df['review'][0]) -
537쪽, 본문 첫 번째 줄
components_는 array[8,
4000]으로 구성돼 있습니다.==>
components_는 array[8,
1000]으로 구성돼 있습니다. -
537쪽, 페이지 하단 Output의 다음 첫 번째 줄을 삭제
(8, 1000) -
565쪽, 페이지 하단 예제 코드의 밑에서 첫 번째 줄
print('Logistic Regression 정확도: ', accuracy_score(test_df['label'], preds)==>
print('Logistic Regression 정확도: ', accuracy_score(test_df['label'], preds)) -
574쪽, 첫 번째 예제 코드
print('name 의 종류 개수 :', df_train['name'].nunique()) print('name sample 7건: \n', df_train['name'][:7]==>
print('name 의 종류 개수 :', mercari_df['name'].nunique()) print('name sample 7건: \n', mercari_df['name'][:7] -
595쪽, 본문 9번째 줄
즉, x2 + 5x + 6을
==>
즉, x2 + 5x + 6을
-
606쪽, 본문 밑에서 3번째 줄
cosine_similarities( ) 호출로 생성된==>
cosine_similarity( ) 호출로 생성된 -
608쪽, 페이지 상단 예제 코드의 4번째 줄
# title_named을 가진 DataFrame의 index 객체를 ndarray로 반환하고==>
# title_name을 가진 DataFrame의 index 객체를 ndarray로 반환하고 -
609쪽, 본문 밑에서 첫 번째 줄
‘
StillUpper Lips’, ‘Me You and Five Bucks’와 같이==>
‘
StiffUpper Lips’, ‘Me You and Five Bucks’와 같이 -
611쪽, 페이지 상단 예제 코드의 2~3번째 줄
m = movies['vote_count'].quantile(percentile) C = movies['vote_average'].mean()==>
m = movies_df['vote_count'].quantile(percentile) C = movies_df['vote_average'].mean() -
611쪽, 페이지 상단 예제 코드의 밑에서 첫 번째 줄
movies['weighted_vote'] = movies.apply(weighted_vote_average, axis=1)==>
movies_df['weighted_vote'] = movies.apply(weighted_vote_average, axis=1) -
620쪽, 페이지 하단 예제 코드의 첫 번째 줄
ratings_pred = predict_rating(ratings_matrix.values, item_simDF.values)==>
ratings_pred = predict_rating(ratings_matrix.values, item_sim_df.values) -
622쪽, 본문 6번째 줄
predict_rating_topsim(ratings_arr, item_sim_arr,
N=20) 함수는 predict_rating( ) 함수와 유사하지만N인자를 가지고 있어서 TOP-N 유사도를 가지는==>
predict_rating_topsim(ratings_arr, item_sim_arr,
n=20) 함수는 predict_rating( ) 함수와 유사하지만n인자를 가지고 있어서 TOP-N 유사도를 가지는 -
623쪽, 페이지 상단 첫 번째 예제 코드의 2번째 줄
olumns = ratings_matrix.columns)==>
columns = ratings_matrix.columns) -
624쪽, 페이지 하단 예제 코드의 7번째 줄
# 사용자가 관람하지 않는 영화명 추출==>
# 사용자가 관람하지 않은 영화명 추출 -
626쪽, 페이지 상단 예제 코드의 다음 8~9번째 줄을 삭제
prev_rmse = 10000 break_count = 0 -
630쪽, 본문 밑에서 7번째 줄
Surprise Dataset 클래스의 load_
bulletin( )은==>
Surprise Dataset 클래스의 load_
builtin( )은 -
636쪽, 페이지 상단 예제 코드의 3번째 줄
reader = Reader(line_format='user item rating timestamp', sep=', ', rating_scale=(0.5, 5))==>
reader = Reader(line_format='user item rating timestamp', sep=',', rating_scale=(0.5, 5)) -
643쪽, 페이지 상단 첫 번째 예제 코드의 3번째 줄
reader = Reader(line_format='user item rating timestamp', sep=', ', rating_scale=(0.5, 5))==>
reader = Reader(line_format='user item rating timestamp', sep=',', rating_scale=(0.5, 5)) -
669쪽, 본문 밑에서 5번째 줄
다양한 환경에 따라
적절한차트를활용합니다.==>
다양한 환경에 따라
적절한 차트를활용합니다. -
672쪽, 본문 밑에서 5번째 줄
먼저 시본의
histpolot( ) 함수를 이용해==>
먼저 시본의
histplot( ) 함수를 이용해 -
679쪽, 페이지 하단 예제 코드의 3번째 줄
plt.plot()==>
plt.show() -
681쪽, 본문 2번째 줄
Estimator=sum으로 설정하면==>
estimator=sum으로 설정하면 -
682쪽, 페이지 하단 예제 코드의 1~3번째 줄
# 아래는 Pclass가 X축값이며 hue파라미터로 Sex를 설정 # 개별 Pclass 값별로 Sex에 따른 Age 평균 값을 구함. sns.barplot(x='Pclass', y='Age', hue='Sex', data=titanic_df)==>
# 개별 Pclass 값별로 Sex에 따른 Survived 평균값을 구함. # Pclass가 X축 값이며 Survived가 Y축 값. hue 파라미터로 Sex를 설정 sns.barplot(x='Pclass', y='Survived', hue='Sex', data=titanic_df)
관련 자료
실습 데이터 다운로드 페이지
- 2장
- 타이타닉 탑승자: https://www.kaggle.com/c/titanic/data
- 3장
- 4장
- 5장
- 6장
- 7장
- 온라인 소매점 데이터 세트: http://archive.ics.uci.edu/ml/datasets/online+retail
- 8장
- IMDB 영화평: https://www.kaggle.com/competitions/word2vec-nlp-tutorial/data
- Opinion Review 데이터 세트: https://archive.ics.uci.edu/ml/datasets/Opinosis+Opinion+%26frasl%3B+Review
- Mercari Price Suggestion Challenge: https://www.kaggle.com/competitions/mercari-price-suggestion-challenge/data
- 9장
- TMDB 5000 영화 데이터 세트: https://www.kaggle.com/datasets/tmdb/tmdb-movie-metadata
- MovieLens 데이터 세트: https://grouplens.org/datasets/movielens/latest/
이 책과 함께 읽으면 좋은 책
데이터ㆍAI 시스템 아키텍트를 위한 실무 가이드
42,000원
중급
 실전! 프로젝트로 배우는 딥러닝 컴퓨터비전
35,000원
중급
실전! 프로젝트로 배우는 딥러닝 컴퓨터비전
35,000원
중급
 머신러닝 엔지니어링 with 파이썬
32,000원
중급
머신러닝 엔지니어링 with 파이썬
32,000원
중급
 마스터링 트랜스포머
35,000원
고급
마스터링 트랜스포머
35,000원
고급