
 데이터ㆍAI 시스템 아키텍트를 위한 실무 가이드
42,000원
중급
데이터ㆍAI 시스템 아키텍트를 위한 실무 가이드
42,000원
중급
도서 소개
저자 소개
역자 소개
목차
예제 코드
정오표
도서 소개
《파이썬 데이터 분석 실무 테크닉 100》은 실제 비즈니스 현장에서 마주칠 수 있는 100개의 예제를 풀면서 현장 분위기를 몸에 익히고 현장에 맞게 기술을 응용하는 힘을 기를 수 있게 설계한 문제집입니다.
이 책에 실린 100개의 테크닉을 익힌다고 해서 바로 현장에 적용할 수 있는 것은 아니지만, 현장 감각을 몸에 익힘으로써 비즈니스 현장에 자연스럽게 투입되기 위한 힘을 기를 수 있습니다. 인터넷이나 입문서로 데이터 분석과 머신러닝을 배우고 나서 ‘붓꽃 분류보다 도움이 되는 데이터 분석을 하고 싶다’, ‘비즈니스 현장에서 이런 기술이 어떻게 응용되는지 알고 싶다’라고 생각하는 사람에게는 이 책이 분명 도움이 될 것입니다.
이 책은 4부로 기초부터 실전까지 폭넓게 구성되어 있습니다.
◎ 1부(기초 편)에서는 비즈니스 현장의 데이터를 분석하기 위해 필요한 데이터 가공 방법을 배웁니다. 비교적 ‘깨끗한’ 인터넷 상품 주문 데이터와 읽어 들이기조차 어려운 ‘지저분한’ 데이터가 많은 대리점 데이터를 예제로 데이터 가공을 실습합니다.
◎ 2부(실전 편1)에서는 머신러닝 기술을 활용해서 고객 분석을 위해 필요한 노하우를 배우고 실제 데이터를 사용해 문제를 발견하고 해결합니다.
◎ 3부(실전 편2)에서는 최적화 기술을 적용하는 노하우를 배우고 경영 상황 개선을 실습해 봅니다.
◎ 4부(발전 편)에서는 AI라고 부르는 이미지 인식 기술과 자연어 처리 기술을 사용해 데이터화되지 않은 정보를 이용해 고객의 잠재적인 수요 파악과 같이 비즈니스 현장에서 활용할 수 있는 노하우를 배우고 실습합니다.
도서 상세 이미지

저자 소개
시모야마 테루마사 (下山 輝昌)
일본전기주식회사(NEC)의 중앙연구소에서 하드웨어 연구 개발 후 독립, 머신러닝을 활용한 데이터 분석, 대시보드 디자인 등 데이터 분석 컨설턴트로 폭넓게 활동했다. 최첨단 기술을 효과적으로 활용해서 회사를 개혁하는 것을 목표로 2017년에 합동회사 아이큐베타(IQBETA LLC.) 공동 창업. 인공지능, Internet of Things(IoT), 정보 디자인의 새로운 방향성과 가능성을 연구하면서 비즈니스화를 진행하고 있다. 공저로는 《Tableau 데이터 분석: 실전에서 활용까지》가 있다.
마쯔다 유마 (松田 雄馬)
박사(공학). 교토대학대학원에서 신경망 기초연구 후 일본전기회사(NEC) 중앙연구소에 입사. 확률론을 이용한 무선통신 신호처리 최적화 연구, 차세대 두뇌형 컴퓨터 프로젝트, 이미지 인식을 중심으로 한 항공우주 방위사업을 포함한 여러 분야의 사업화 담당. 2015년 동북대학교대학원에서 박사 취득, 2017년 합동회사 아이큐베타(IQBETA LLC.) 공동 창업. 저서로 《인공지능 철학》 《인공지능은 왜 의자에 못 앉는가》가 있다.
미키 타카유키 (三木 孝行)
은행, 철도 계열의 업무기간시스템 개발을 요건 정의부터 설계, 개발, 릴리스까지 폭넓게 경험하였다. 업무기반시스템에서는 꼭 필요한 데이터베이스 사용을 위해, 특별히 RDB/SQL에 대한 지식을 습득하고 있다. 이 경험을 살려서 데이터 분석과 데이터 가공을 포함한 시스템 개발 전반의 컨설턴트로 폭넓게 담당하고 있다. 2017년에 합동회사 아이큐베타(IQBETA LLC.)를 공동 창업하였다.
역자 소개
손민규
소니 반도체에서 데이터 분석을 활용한 알고리즘 및 시스템 개발 업무를 했다. 현재 삼성전자에서 관련 데이터 분석 업무를 하고 있으며 사원을 대상으로 통계 알고리즘 강의를 진행했다. 일본 규슈대학교에서 인공지능의 한 분야인 Reinforcement Learning 알고리즘 개발로 박사학위를 받았으며 관심 분야는 Reinforcement Learning, Neural Network, Genetic Algorithm 등 Machine Learning Algorithm을 활용한 시스템 개발이다.
저서로는 『데이터 분석을 떠받치는 수학 개정판(2020)』 『기초부터 시작하는 강화학습/신경망 알고리즘(2019)』이 있으며 『정석으로 배우는 딥러닝(2017)』을 감수하였고 『가장 쉬운 딥러닝 입문 교실(2018), 실전! 딥러닝(2019)』을 번역하였다.
목차
- [1부] 기초편: 데이터 가공
- ▣ 01장: 웹에서 주문 수를 분석하는 테크닉 10
- 001 데이터를 읽어 들이자
- 002 데이터를 결합(유니언)해 보자
- 003 매출 데이터끼리 결합(조인)해 보자
- 004 마스터데이터를 결합(조인)해 보자
- 005 필요한 데이터 칼럼을 만들자
- 006 데이터를 검산하자
- 007 각종 통계량을 파악하자
- 008 월별로 데이터를 집계해 보자
- 009 월별, 상품별로 데이터를 집계해 보자
- 010 상품별 매출 추이를 가시화해 보자
- ▣ 02장: 대리점 데이터를 가공하는 테크닉 10
- 011 데이터를 읽어 들이자
- 012 데이터의 오류를 살펴보자
- 013 데이터에 오류가 있는 상태로 집계해 보자
- 014 상품명 오류를 수정하자
- 015 금액의 결측치를 수정하자
- 016 고객 이름의 오류를 수정하자
- 017 날짜 오류를 수정하자
- 018 고객 이름을 키로 두 개의 데이터를 결합(조인)하자
- 019 정제한 데이터를 덤프하자
- 020 데이터를 집계하자
- ▣ 01장: 웹에서 주문 수를 분석하는 테크닉 10
- [2부] 실전편①: 머신러닝
- ▣ 03장: 고객의 전체 모습을 파악하는 테크닉 10
- 021 데이터를 읽어 들이고 확인하자
- 022 고객 데이터를 가공하자
- 023 고객 데이터를 집계하자
- 024 최신 고객 데이터를 집계하자
- 025 이용 이력 데이터를 집계하자
- 026 이용 이력 데이터로부터 정기 이용 플래그를 작성하자
- 027 고객 데이터와 이용 이력 데이터를 결합하자
- 028 회원 기간을 계산하자
- 029 고객 행동의 각종 통계량을 파악하자
- 030 탈퇴 회원과 지속 회원의 차이를 파악하자
- ▣ 04장: 고객의 행동을 예측하는 테크닉 10
- 031 데이터를 읽어 들이고 확인하자
- 032 클러스터링으로 회원을 그룹화하자
- 033 클러스터링 결과를 분석하자
- 034 클러스터링 결과를 가시화하자
- 035 클러스터링 결과를 바탕으로 탈퇴 회원의 경향을 파악하자
- 036 다음 달의 이용 횟수 예측을 위해 데이터를 준비하자
- 037 특징이 되는 변수를 추가하자
- 038 다음 달 이용 횟수를 예측하는 모델을 구축하자
- 039 모델에 기여하는 변수를 확인하자
- 040 다음 달의 이용 횟수를 예측하자
- ▣ 05장: 회원 탈퇴를 예측하는 테크닉 10
- 041 데이터를 읽어 들이고 이용 데이터를 수정하자
- 042 탈퇴 전월의 탈퇴 고객 데이터를 작성하자
- 043 지속 회원의 데이터를 작성하자
- 044 예측할 달의 재적 기간을 작성하자
- 045 결측치를 제거하자
- 046 문자열 변수를 처리할 수 있게 가공하자
- 047 의사결정 트리를 사용해서 탈퇴 예측 모델을 구축하자
- 048 예측 모델을 평가하고 모델을 튜닝해 보자
- 049 모델에 기여하는 변수를 확인하자
- 050 회원 탈퇴를 예측하자
- ▣ 03장: 고객의 전체 모습을 파악하는 테크닉 10
- [3부] 실전편②: 최적화 문제
- ▣ 06장: 물류의 최적경로를 컨설팅하는 테크닉 10
- 051 물류 데이터를 불러오자
- 052 현재 운송량과 비용을 확인해 보자
- 053 네트워크를 가시화해 보자
- 054 네트워크에 노드를 추가해 보자
- 055 경로에 가중치를 부여하자
- 056 운송 경로 정보를 불러오자
- 057 운송 경로 정보로 네트워크를 가시화해 보자
- 058 운송 비용 함수를 작성하자
- 059 제약 조건을 만들어보자
- 060 운송 경로를 변경해서 운송 비용 함수의 변화를 확인하자
- ▣ 07장: 물류 네트워크 최적 설계를 위한 테크닉 10
- 061 운송 최적화 문제를 풀어보자
- 062 최적 운송 경로를 네트워크로 확인하자
- 063 최적 운송 경로가 제약 조건을 만족하는지 확인하자
- 064 생산 계획 데이터를 불러오자
- 065 이익을 계산하는 함수를 만들자
- 066 생산 최적화 문제를 풀어보자
- 067 최적 생산 계획이 제약 조건을 만족하는지 확인하자
- 068 물류 네트워크 설계 문제를 풀어보자
- 069 최적 네트워크의 운송 비용과 그 내역을 계산하자
- 070 최적 네트워크의 생산 비용과 그 내역을 계산하자
- ▣ 08장: 수치 시뮬레이션으로 소비자의 행동을 예측하는 테크닉 10
- 071 인간관계 네트워크를 가시화해 보자
- 072 입소문에 의한 정보 전파 모습을 가시화해 보자
- 073 입소문 수의 시계열 변화를 그래프화해 보자
- 074 회원 수의 시계열 변화를 시뮬레이션해 보자
- 075 파라미터 전체를 ‘상관관계’를 보면서 파악해 보자
- 076 실제 데이터를 불러와보자
- 077 링크 수의 분포를 가시화해 보자
- 078 시뮬레이션을 위해 실제 데이터로부터 파라미터를 추정하자
- 079 실제 데이터와 시뮬레이션을 비교하자
- 080 시뮬레이션으로 미래를 예측해 보자
- ▣ 06장: 물류의 최적경로를 컨설팅하는 테크닉 10
- [4부] 발전편: 이미지 처리 / 언어 처리
- ▣ 09장: 잠재고객을 파악하기 위한 이미지 인식 테크닉 10
- 081 이미지 데이터를 불러오자
- 082 동영상 데이터를 불러오자
- 083 동영상을 이미지로 나누고 저장하자
- 084 이미지 속에 사람이 어디에 있는지 검출해 보자
- 085 이미지 속 사람 얼굴을 검출해 보자
- 086 이미지 속 사람의 얼굴이 어느 쪽을 보고 있는지 검출해 보자
- 087 검출한 정보를 종합해서 타임랩스를 만들어보자
- 088 전체 모습을 그래프로 가시화해 보자
- 089 거리의 변화를 그래프로 확인해 보자
- 090 이동 평균을 계산해서 노이즈를 제거하자
- ▣ 10장: 앙케트 분석을 위한 자연어 처리 테크닉 10
- 091 데이터를 불러서 파악해 보자
- 092 불필요한 문자를 제거하자
- 093 문자 수를 세어 히스토그램으로 표시해 보자
- 094 형태소 분석으로 문장을 분해해 보자
- 095 형태소 분석으로 문장에서 ‘동사’, ‘명사’를 추출해 보자
- 096 형태소 분석으로 자주 나오는 명사를 확인해 보자
- 097 관계없는 단어를 제거해 보자
- 098 고객만족도와 자주 나오는 단어의 관계를 살펴보자
- 099 의견을 특징으로 표현해 보자
- 100 비슷한 설문지를 찾아보자
- ▣ 부록
- 001 데이터 결합과 정규화
- 002 머신러닝
- 003 최적화 문제
- ▣ 맺음말
- ▣ 09장: 잠재고객을 파악하기 위한 이미지 인식 테크닉 10
예제 코드
- GitHub 저장소: https://github.com/wikibook/pyda100
- ZIP 형식으로 다운로드: https://github.com/wikibook/pyda100/archive/master.zip
정오표
코드 개선
-
21쪽, 페이지 중간 예제 코드
join_data.groupby("payment_month").sum()["price"]==>
join_data.groupby('payment_month')['price'].sum()
정오표
-
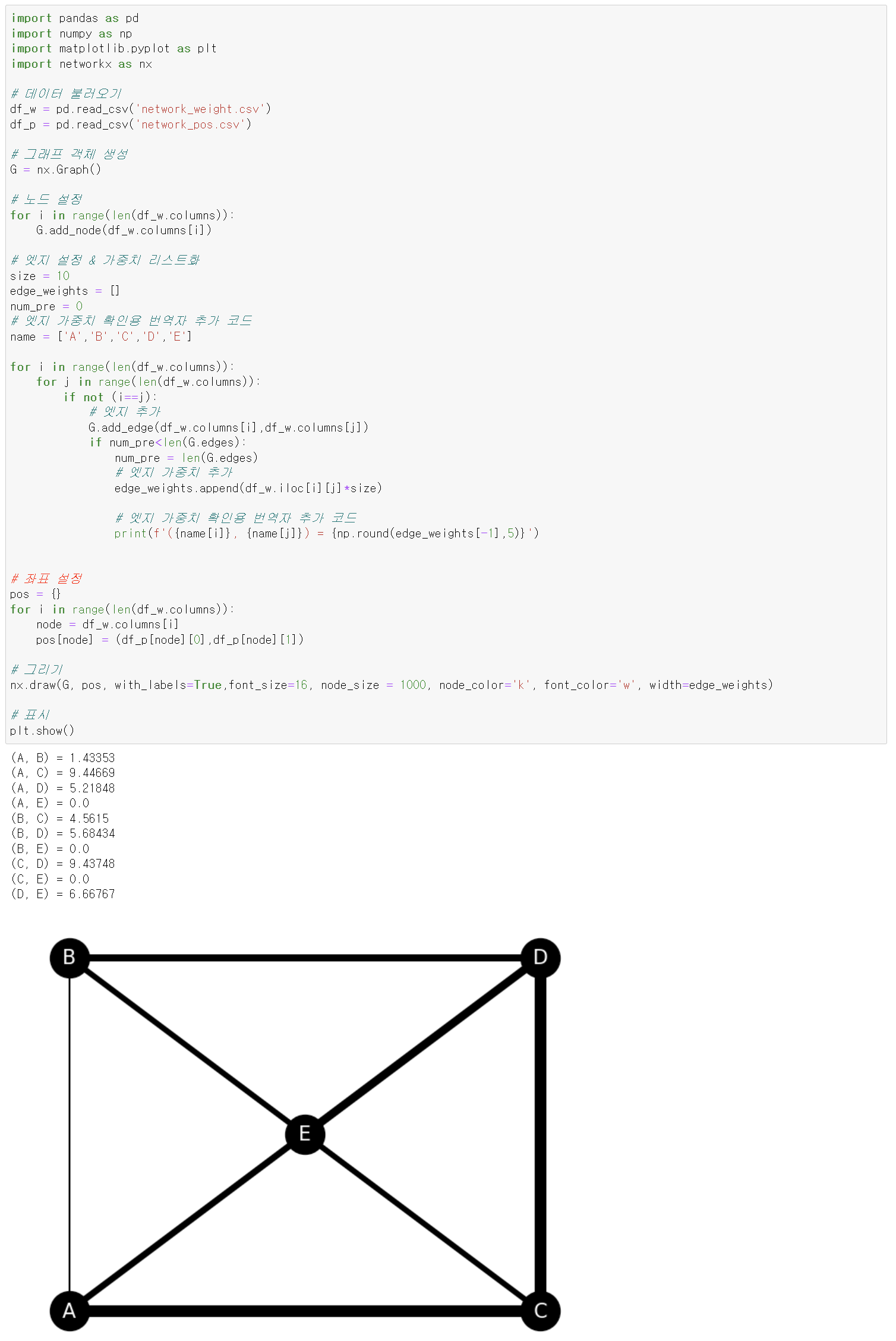
143쪽, 테크닉 55의 예제 코드를 다음 코드로 교체
import pandas as pd import numpy as np import matplotlib.pyplot as plt import networkx as nx # 데이터 불러오기 df_w = pd.read_csv('network_weight.csv') df_p = pd.read_csv('network_pos.csv') # 그래프 객체 생성 G = nx.Graph() # 노드 설정 for i in range(len(df_w.columns)): G.add_node(df_w.columns[i]) # 엣지 설정 & 가중치 리스트화 size = 10 edge_weights = [] num_pre = 0 # 엣지 가중치 확인용 번역자 추가 코드 name = ['A','B','C','D','E'] for i in range(len(df_w.columns)): for j in range(len(df_w.columns)): if not (i==j): # 엣지 추가 G.add_edge(df_w.columns[i],df_w.columns[j]) if num_pre<len(G.edges): num_pre = len(G.edges) # 엣지 가중치 추가 edge_weights.append(df_w.iloc[i][j]*size) # 엣지 가중치 확인용 번역자 추가 코드 print(f'({name[i]}, {name[j]}) = {np.round(edge_weights[-1],5)}') # 좌표 설정 pos = {} for i in range(len(df_w.columns)): node = df_w.columns[i] pos[node] = (df_p[node][0],df_p[node][1]) # 그리기 nx.draw(G, pos, with_labels=True,font_size=16, node_size = 1000, node_color='k', font_color='w', width=edge_weights) # 표시 plt.show() -
145쪽, 그림 6-13을 다음 그림으로 교체
이 책과 함께 읽으면 좋은 책
데이터ㆍAI 시스템 아키텍트를 위한 실무 가이드
42,000원
중급
 실전! 프로젝트로 배우는 딥러닝 컴퓨터비전
35,000원
중급
실전! 프로젝트로 배우는 딥러닝 컴퓨터비전
35,000원
중급
 머신러닝 엔지니어링 with 파이썬
32,000원
중급
머신러닝 엔지니어링 with 파이썬
32,000원
중급
 마스터링 트랜스포머
35,000원
고급
마스터링 트랜스포머
35,000원
고급