


 데이터ㆍAI 시스템 아키텍트를 위한 실무 가이드
42,000원
중급
데이터ㆍAI 시스템 아키텍트를 위한 실무 가이드
42,000원
중급
데이터 사이언스
데이터 애널리틱스
예제로 배우는 모델링 기법, 데이터 분석, 모델 구축 과정
지은이 이재식
도서 정보
- 출간일
- 2020년 9월 2일
- 쪽수
- 536쪽
- ISBN
- 9791158391737
- 시리즈
- 데이터 사이언스 시리즈_061
- 정가
- 35,000원
- 난이도
-
입문 초급 중급 고급
도서 소개
저자 소개
목차
예제 코드
정오표
관련 자료
도서 소개
데이터 애널리틱스는 데이터로부터 유용한 정보와 지식을 도출하기 위한 모델링 기법들, 그 기법들로 데이터를 분석하는 과정, 그리고 신뢰할 수 있는 방법과 원칙에 입각하여 모델을 구축하는 과정 전반을 일컫는 용어다. 이 책은 데이터 애널리틱스에 대한 모든 주제를 상세한 예제 풀이를 통해서 설명한다. 모델링 기법에 대한 이론 및 모델의 구축 과정에 대한 설명을 간단한 예제의 데이터 분석으로부터 시작해서 복잡한 예제로 끝을 맺는다. 따라서 데이터 애널리틱스를 처음 접하는 독자는 이 책을 통해서 데이터 애널리틱스에 입문할 수 있고, 데이터 애널리틱스를 전공하는 독자는 자신의 지식을 심화시킬 수 있다. 각 모델링 기법에 대한 설명 후에는 R 및 R-텐서플로를 사용해서 데이터를 분석하고 모델을 구축하는 프로그램이 수록되어 있어서 직접 실습 경험을 쌓을 수 있다.
★ 이 책에서 다루는 내용 ★
- 데이터 마이닝
- 머신러닝
- 모델의 구축
- 회귀 분석
- 로지스틱 회귀 분석
- 선형 판별 분석
- 베이즈 분류기
- 군집 분석
- 연관 분석
- 순차 패턴 분석
- 의사결정 트리
- 랜덤 포레스트
- 라쏘 회귀 분석
- 릿지 회귀 분석
- 일래스틱 네트 회귀 분석
- 서포트 벡터 머신
- 인공 신경망
- 심층 신경망
- 합성곱 신경망
- 순환 신경망
도서 상세 이미지

저자 소개
이재식
-
서울대학교 경영대학 경영학과 경영학사
-
한국과학기술원(KAIST) 산업공학과 공학석사
-
미국 펜실베이니아 대학교 와튼 스쿨(Wharton School) 경영정보시스템 전공 경영학박사
-
아주대학교 경영대학 교수
-
한국전문가시스템학회 학회지 편집위원장
-
교육부 Brain Korea 21 사업 ‘데이터 마이닝 연구팀’ 책임교수
-
한국지능정보시스템학회 회장
-
정보통신부 ‘유비쿼터스 환경에서의 데이터 마이닝 기술 개발 연구팀’ 책임교수
-
한국지능정보시스템학회지 1995~2014 피인용 논문 대상 수상
목차
- [01부] 기본 개념
- ▣ 01장: 서론
- 1 인공지능, 머신러닝, 딥러닝
- 2 데이터 사이언스와 데이터 애널리틱스
- 3 데이터 마이닝과 데이터 애널리틱스
- 4 이 책의 구성
- 5 참고문헌
- ▣ 02장: 데이터 마이닝
- 1 데이터, 정보, 지식
- 2 데이터의 속성
- 2.1 범주형 속성
- 2.2 수치형 속성
- 2.3 기타 속성
- 3 데이터 마이닝의 탄생
- 4 데이터 마이닝의 정의
- 4.1 비즈니스 프로세스
- 4.2 대량의 데이터
- 4.3 의미 있는 패턴과 규칙
- 5 데이터 마이닝의 유형
- 5.1 가설 검정
- 5.2 방향성 데이터 마이닝
- 5.3 무방향성 데이터 마이닝
- 6 데이터 마이닝의 단계
- 6.1 KDD2.0
- 6.2 CRISP-DM
- 6.3 두 방법론의 비교
- 7 참고문헌
- ▣ 03장: 머신러닝
- 1 문제를 푸는 방법
- 2 머신러닝의 정의
- 3 머신러닝의 유형
- 3.1 지도 학습
- 3.2 비지도 학습
- 3.3 준지도 학습
- 3.4 강화 학습
- 4 머신러닝의 기법들
- 4.1 지도 학습 기법
- 4.2 비지도 학습 기법
- 4.3 준지도 학습 기법
- 4.4 강화 학습 기법
- 5 참고문헌
- ▣ 04장: 모델 구축
- 1 모델의 정의
- 2 모델의 구축 과정
- 2.1 훈련 데이터 집합의 용도
- 2.2 과대적합의 발생
- 2.3 검증 데이터 집합의 용도
- 2.4 테스트 데이터 집합의 용도
- 2.5 스코어 데이터 집합의 용도
- 3 편향되지 않은 모델의 구축
- 3.1 반복적 무작위 서브샘플링 검증 방법
- 3.2 K-폴드 교차 검증 방법
- 3.3 단일 관측값 제거 교차 검증 방법
- 3.4 부트스트랩 방법
- 4 모델의 평가
- 4.1 회귀 평가 척도
- 4.2 분류 평가 척도
- 5 편향과 편차 간의 상충 관계
- 5.1 훈련 데이터 집합의 평균으로 만든 모델
- 5.2 선형 회귀 모델
- 5.3 2차 다항 회귀 모델
- 5.4 6차 다항 회귀 모델
- 5.5 네 개 모델의 비교
- 6 과대적합의 방지 또는 제거
- 6.1 속성 선정
- 6.2 균등화
- 6.3 조기 종료
- 6.4 드롭아웃과 배치 정규화
- 6.5 가지치기
- 6.6 앙상블 방법
- 7 모델 데이터 집합
- 7.1 모델 데이터 집합의 크기와 밀도
- 7.2 오버샘플링
- 7.3 결측값
- 8 모델의 비교 및 선정
- 8.1 ROC 곡선의 비교
- 8.2 통계적 검정에 의한 비교
- 9 앙상블 방법에 의한 모델의 성능 향상
- 9.1 앙상블 방법
- 9.2 배깅 방법
- 9.3 부스팅 방법
- 10 참고문헌
- [02부] 통계학 기반 기법
- ▣ 05장: 회귀분석
- 1 회귀 분석
- 2 단순 회귀 분석
- 2.1 베타햇 값 구하기: 최소자승법
- 2.2 결정계수 R2
- 2.3 단순 회귀 분석의 예제
- 3 다중 회귀 분석
- 3.1 다중 회귀 분석의 예제
- 3.2 단계별 회귀 분석
- 3.3 조정된 결정계수
- 4 다중 회귀 분석을 이용한 자동차 연비 추정
- 4.1 A_Model: 모든 변수를 사용한 모델
- 4.2 F_Model: 전방향 선택으로 선택한 변수를 사용한 모델
- 4.3 B_Model: 역방향 제거로 선택한 변수를 사용한 모델
- 4.4 S_Model: 양방향 선택과 제거로 선택한 변수를 사용한 모델
- 4.5 P_Model: Pr(>|t|)가 유의한 변수를 사용한 모델
- 4.6 최종 모델의 선정
- 5 참고문헌
- ▣ 06장: 로지스틱 회귀 분석
- 1 로지스틱 회귀 분석
- 2 이진형 문제의 선형 회귀 모델
- 3 이진형 문제의 로지스틱 회귀 모델
- 4 로지스틱 회귀 분석을 이용한 잡지 구독 예측
- 4.1 A_loModel: 모든 변수를 사용한 모델
- 4.2 S_loModel: 양방향 선택과 제거로 선택한 변수를 사용한 모델
- 4.3 P_loModel: Pr(>|z|)가 유의한 변수를 사용한 모델
- 4.4 최종 모델의 선정
- 5 참고문헌
- ▣ 07장: 선형 판별 분석
- 1 선형 판별 분석
- 2 선형 판별 분석 방법
- 2.1 중심과의 거리를 이용하는 방법
- 2.2 회귀를 이용하는 방법
- 2.3 피셔의 선형 판별 방법
- 3 선형 판별 분석을 이용한 대출 결정
- 4 참고문헌
- ▣ 08장: 베이즈 분류기
- 1 베이즈 분류기
- 2 베이즈 정리
- 3 베이즈 분류기의 이해
- 4 베이즈 분류기의 예제
- 4.1 수치형 변수가 없는 경우: 예제 8.1
- 4.2 구매 여부 개수가 0일 경우
- 4.3 수치형 변수가 있는 경우: 예제 8.2
- 5 베이즈 분류기를 이용한 스팸 메일 판정
- 6 참고문헌
- [03부] 머신러닝 기반 기법
- ▣ 09장: 군집 분석
- 1 군집 분석
- 2 군집의 의미
- 3 근접성
- 3.1 수치형 속성
- 3.2 범주형 속성
- 3.3 군집 간의 거리 측정
- 4 클러스터링 결과의 평가 척도
- 5 클러스터링을 위한 데이터 준비
- 5.1 속성값 조정
- 5.2 가중치 부여
- 6 계층적 클러스터링: 예제 9.1
- 6.1 병합적 클러스터링
- 6.2 분할적 클러스터링
- 6.3 클러스터링 결과의 평가
- 7 K-평균 클러스터링
- 7.1 K-평균 클러스터링의 단계
- 7.2 K-평균 클러스터링: 예제 9.2
- 7.3 초기 무작위 중심의 선택
- 7.4 K값의 설정
- 8 K-평균 클러스터링을 이용한 피교육자 군집 분석
- 9 참고문헌
- ▣ 10장: 연관 분석
- 1 연관 분석
- 2 연관 규칙
- 3 연관 규칙의 도출 과정
- 3.1 아이템의 상세화 수준 결정
- 3.2 거래 데이터로부터 아이템집합 생성
- 3.3 아이템집합이 판매된 거래 건수와 확률 산출
- 3.4 아이템집합 가지치기
- 3.5 연관 규칙 생성
- 3.6 생성된 연관 규칙 평가
- 4 연관 규칙 도출 연습
- 5 연관 분석을 이용한 시장바구니 분석
- 6 순차 패턴 분석
- 7 유용한 순차 패턴의 발견
- 8 순차 패턴 분석을 이용한 제품 구매 순서 분석
- 9 참고문헌
- ▣ 11장: 의사결정 트리
- 1 의사결정 트리
- 2 의사결정 트리의 용도
- 2.1 분류
- 2.2 점수 부여
- 2.3 추산
- 3 의사결정 트리의 형태
- 4 의사결정 트리의 구축
- 4.1 기본 과정
- 4.2 분지
- 4.3 의사결정 트리의 구축 단계
- 4.4 의사결정 트리의 평가
- 4.5 의사결정 트리에서 규칙의 추출
- 5 최상 분지 속성의 선정
- 5.1 분지 속성 선정의 중요성
- 5.2 최상 분지 속성의 선정 기준
- 5.3 최상 분지 속성의 선정 과정
- 6 의사결정 트리 구축 과정의 예제
- 6.1 엔트로피 분지 방법
- 6.2 지니 분지 방법
- 7 의사결정 트리의 가지치기
- 7.1 가지치기의 필요성
- 7.2 오류 감소 가지치기
- 8 의사결정 트리를 이용한 개인 신용 평가
- 9 참고문헌
- ▣ 12장: 랜덤 포레스트
- 1 랜덤 트리
- 2 랜덤 포레스트
- 3 랜덤 포레스트를 이용한 고객 이탈 예측
- 4 참고문헌
- ▣ 13장: 새로운 회귀 분석 기법들
- 1 균등화된 회귀 분석
- 1.1 균등화
- 1.2 균등화된 회귀 분석의 유형
- 1.3 엑셀을 사용한 균등화된 회귀 분석
- 2 균등화된 회귀 분석을 이용한 자동차 연비 추정
- 3 베타햇 값 구하기: 기울기 하강법
- 4 기울기 하강법을 이용한 회귀 모델 구축
- 4.1 R을 사용한 기울기 하강법
- 4.2 텐서플로를 사용한 기울기 하강법
- 5 참고문헌
- 1 균등화된 회귀 분석
- ▣ 14장: 서포트 벡터 머신
- 1 서포트 벡터 머신
- 2 서포트 벡터 머신의 이해
- 3 서포트 벡터 머신의 최적화 문제 수식화
- 4 엑셀을 사용한 서포트 벡터 머신: 예제 14.1
- 5 선형 분리 불가능 문제: 여유 변수의 도입
- 5.1 여유 변수를 도입한 SVM의 최적화 문제 수식
- 5.2 엑셀을 사용한 SVM: 예제 14.2
- 5.3 균등화 파라미터
- 6 선형 분리 불가능 문제: 커널 트릭의 사용
- 6.1 엑셀을 사용한 SVM: 예제 14.3
- 6.2 커널 함수
- 6.3 엑셀을 사용한 SVM: 예제 14.4
- 7 서포트 벡터 머신을 이용한 유방암 판정
- 8 참고문헌
- ▣ 15장: 인공 신경망
- 1 인공 신경망
- 2 인공 신경망의 구성
- 2.1 처리 요소
- 2.2 처리 요소의 입력과 출력
- 2.3 처리 요소의 결합과 계층의 결합
- 2.4 가중치와 활성 함수
- 2.5 학습 기능
- 3 역전파 알고리즘
- 3.1 전방향 단계
- 3.2 역방향 단계
- 3.3 역전파 알고리즘의 과정: 예제 15.1
- 3.4 가중치 수정의 빈도
- 4 활성 함수
- 5 비선형 분류
- 6 XOR 문제를 푸는 인공 신경망: 예제 15.2
- 7 범주형 속성의 인코딩
- 7.1 N개-중-1개 인코딩
- 7.2 N개-중-M개 인코딩
- 7.3 온도계 인코딩
- 8 인공 신경망을 이용한 심장질환 판정
- 9 참고문헌
- ▣ 16장: 딥러닝
- 1 딥러닝의 개요
- 1.1 기울기 소실 현상
- 1.2 기울기 소실 현상의 극복
- 1.3 과대적합의 방지
- 2 심층 신경망
- 2.1 심층 신경망을 이용한 동물 유형 판정
- 3 합성곱 신경망
- 3.1 합성곱 계층
- 3.2 풀링 계층
- 3.3 합성곱 신경망의 차원 계산
- 3.4 합성곱 신경망을 이용한 필기체 숫자 판독
- 4 순환 신경망
- 4.1 순환 신경망 구조의 유형
- 4.2 초기 순환 신경망 모델의 단점 극복
- 4.3 순환 신경망을 이용한 문장 예측
- 4.4 순환 신경망을 이용한 감성 분석
- 5 참고문헌
- 1 딥러닝의 개요
- ▣ 부록A: R 설치하기
- ▣ 부록B: R Studio 설치하기
- ▣ 부록C: Anaconda, R, R Studio, Tensorflow 설치하기
- ▣ 부록D: R 환경의 Tensorflow 2.0 버전 코드
예제 코드
- 예제 코드 실행에 필요한 데이터는 [관련 자료] 탭에서 내려받으실 수 있습니다.
정오표
-
119쪽, 표 5.10의 제목
표 5.10 '무의미' 변수가 추가된 메이저 리그 데이터
==>
표 5.10 '무의미' 변수가 추가된 Baseball 데이터
-
258쪽, 그림 10.8의 (1) R Code
R Code 수행에 에러는 없지만, beerchecken을 beerchicken으로 수정함.
-
424쪽, 본문 마지막 단락
neuralnet 함수에서는 지금까지 배운 모델링 함수와 다르게 수식을 전부 써야 한다. 그림 15.17의 R Code는 데이터를 읽어 들인 후에 neuralnet 함수에서 사용할 수식 formula_Ann을 만드는 작업이다.
==>
Heart.csv에서 목표속성은 disease이다. 만일 입력속성 전부를 사용해서 모델을 구축한다면, 다른 모델링 함수와 마찬가지로 모델 식을 disease~.로 쓰면 된다. 하지만 이번에는 속성의 이름을 전부 사용해서 모델 식을 만들어 보자. 이렇게 하면 모델 식에서 입력속성 일부를 빼거나 다시 넣기가 쉬워진다. 그림 15.17의 R Code는 데이터를 읽어 들인 후에 neuralnet 함수에서 사용할 모델 식 formula_Ann을 만드는 작업이다.
-
427쪽, 본문 마지막 단락의 마지막 문장인 아래의 글을 삭제함.
"ANN에서 예측을 수행하는 함수의 이름은 'compute'다."
-
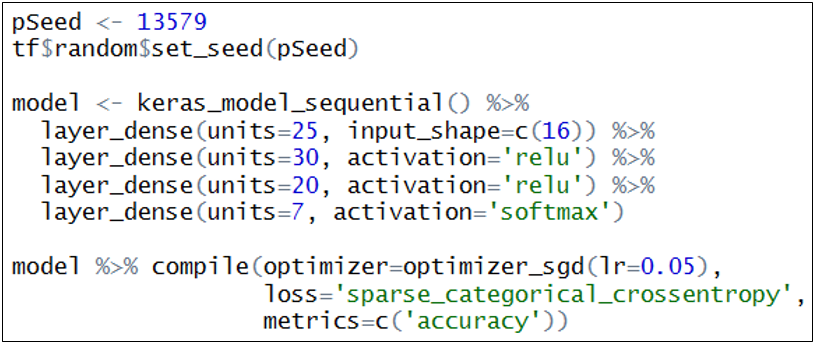
427쪽, R Code 수행에 에러는 없지만, 그림 15.21을 아래의 그림으로 교체함.

-
430쪽, R Code 수행에 에러는 없지만, 그림 15.24를 아래의 그림으로 교체함.

-
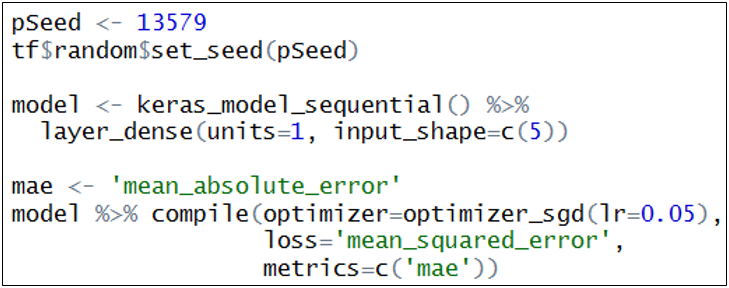
506쪽, R Code 수행에 에러는 없지만, 그림 D13.2를 아래의 그림으로 교체함.

-
508쪽, R Code 수행에 에러는 없지만, 그림 D16.2를 아래의 그림으로 교체함.

관련 자료
- GitHub 저장소: https://github.com/wikibook/data-analytics
- ZIP 형식으로 다운로드: https://github.com/wikibook/data-analytics/archive/master.zip
이 책과 함께 읽으면 좋은 책
데이터ㆍAI 시스템 아키텍트를 위한 실무 가이드
42,000원
중급
 BEST
실전! 프로젝트로 배우는 딥러닝 컴퓨터비전
35,000원
중급
BEST
실전! 프로젝트로 배우는 딥러닝 컴퓨터비전
35,000원
중급
 머신러닝 엔지니어링 with 파이썬
32,000원
중급
머신러닝 엔지니어링 with 파이썬
32,000원
중급
 마스터링 트랜스포머
35,000원
고급
마스터링 트랜스포머
35,000원
고급